In modern e-commerce, latency is a revenue killer. When a user clicks “Buy,” they expect instant feedback. From a systems perspective, the goal is to keep the hot path (customer interaction) short, predictable, and failure-tolerant, without compromising inventory correctness or auditability.
Inspired by the article Serverless Order Management using AWS Step Functions and DynamoDB, we’ll take a sovereignty- and security-first approach to build a high-speed, resilient order workflow using Taubyte, optimized for the moment that matters: when a customer presses “Buy.”
Instead of coupling checkout to a centralized database write (or a long orchestration chain), we separate concerns:
- Hot path: accept the order, take payment, reserve stock (fast, close to users)
- Cold path: reconcile final state into the system of record, with retries and observability
The Challenge: Speed vs. Consistency
Traditional order processing systems face a fundamental trade-off:
- Fast systems can become risky (overselling, partial failures, messy recovery)
- Strongly consistent systems often feel slow because every step synchronizes on a central system of record
- Orchestrated workflows add hop count, state management overhead, and complicated failure handling
Our Taubyte-based architecture solves all three problems simultaneously.
The Architecture Overview
We remove the “central database bottleneck” from the customer checkout experience by using a familiar distributed-systems pattern:
- Write-ahead state in a fast distributed store (orders, payment status, reservation state)
- Background convergence to the system of record (ERP/OMS/warehouse DB) with retries
The Taubyte building blocks (architect view):
- Functions: stateless request handlers and workflow steps (hot path + background steps)
- Distributed caches: low-latency, globally available key-value stores for orders and stock state
- Scheduled jobs: periodic reconciliation tasks (inbound inventory refresh, outbound order finalization)
Below is the complete workflow we will be implementing.
 (Caption: The complete asynchronous order processing and synchronization workflow.)
(Caption: The complete asynchronous order processing and synchronization workflow.)
The Workflow: The “Hot Path”
The initial steps must be fast because they are directly tied to conversion rate. The key design decision: avoid blocking the checkout flow on synchronous writes to the system of record.
1. Order Registration & Caching
The process begins when a user submits an order. A Taubyte function handles the request and responds quickly. (Under the hood, Taubyte uses WebAssembly for fast startup, reducing cold-start impact.)
Instead of going straight to a heavyweight database, the function immediately writes the order to the Order Cache. Think of this as the workflow’s durable “working set” during checkout: the order state machine lives here until it is finalized.
2. Payment Processing
Next comes payment. A function calls your Payment Provider (e.g., Stripe). The result (success/failure) is written back into the Order Cache immediately, keeping the workflow state centralized without involving the system of record in the hot path.
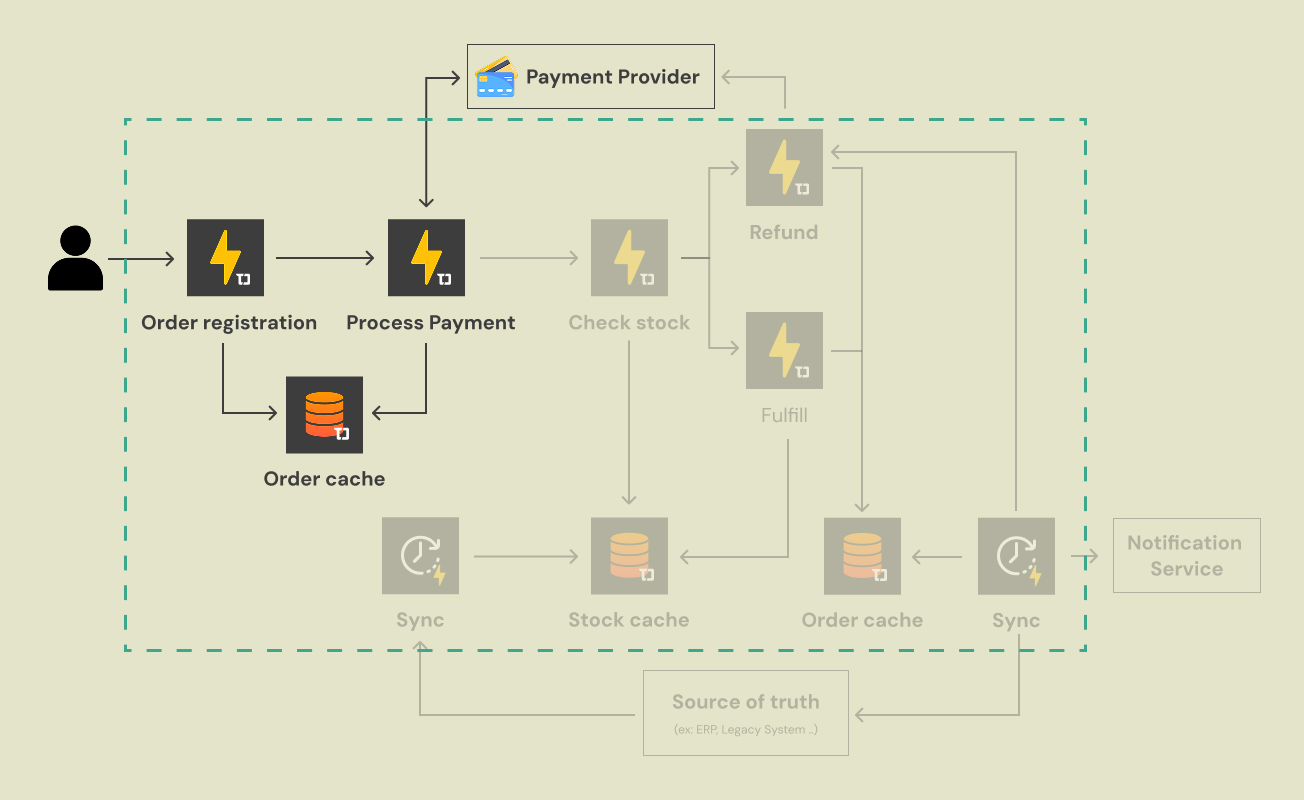 (Caption: The high-speed intake. User requests are immediately accepted and stored in a fast distributed cache, decoupling the user from backend complexity.)
(Caption: The high-speed intake. User requests are immediately accepted and stored in a fast distributed cache, decoupling the user from backend complexity.)
The Inventory Decision Engine (Preventing Oversell)
The most critical risk here is overselling. We prevent it without slowing down checkout by using a fast inventory working set and reservation semantics in the hot path, then reconciling with the back-office system afterward.
3. The Inventory Check
When it’s time to confirm availability, we don’t call a distant back-office inventory system in the middle of the checkout. We query the Stock Cache instead, a fast working set that holds the latest available counts per item.
The logic is simple:
- Fetch: Get current item count from the Stock Cache.
- Decision:
- If inventory is available (at least one unit): Proceed to fulfillment.
- If inventory is not available (zero units), or payment failed: Proceed to refund.
Branch A: Fulfillment (The Happy Path)
If stock is available, we proceed to fulfillment. At this moment, we reserve the inventory immediately in the Stock Cache so two customers can’t buy the last unit at the same time. In practice, this implies a safe “reserve” operation and a clear policy for releasing reservations on failure or timeout.
Branch B: Refund (The Failure Path)
If the cache indicates out-of-stock (or payment failed), we trigger a refund and notify the customer. The key is that failure handling is part of the workflow, not an afterthought.
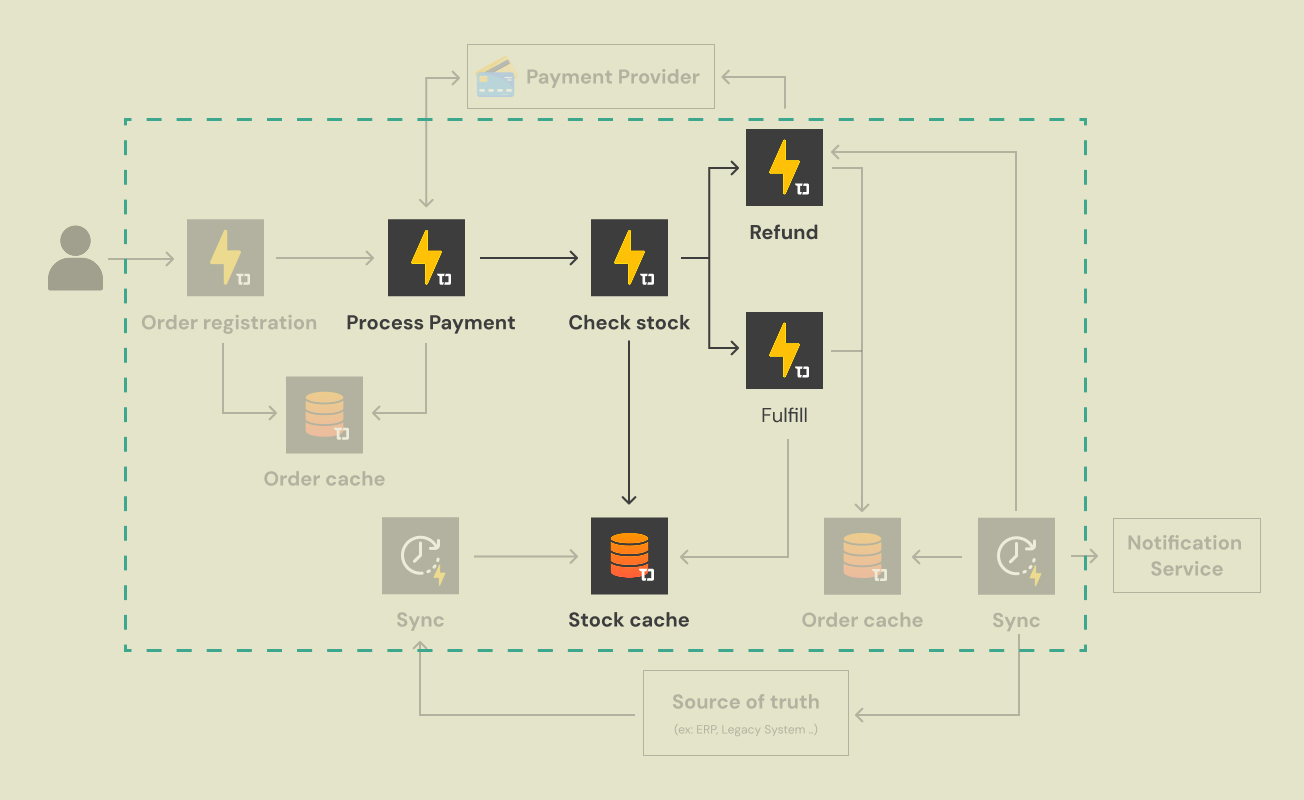 (Caption: The decision engine. The system uses a fast cache lookup to determine available stock, splitting the workflow into fulfillment or refund paths.)
(Caption: The decision engine. The system uses a fast cache lookup to determine available stock, splitting the workflow into fulfillment or refund paths.)
The Secret Sauce: Asynchronous Synchronization
You might be asking: “If we’re using a distributed working set to go fast, how do we guarantee correctness and auditability?”
The answer is background reconciliation: accept and process orders quickly, then converge final state into the system of record with retryable, observable workers.
The Inbound Sync (Keeping Stock Accurate)
We cannot rely solely on the cache forever, as inventory might change due to external factors (e.g., warehouse restocks).
We define a Taubyte scheduled job that runs periodically (e.g., every 5 minutes).
- Task: Pull the latest inventory from your system of record (ERP/warehouse DB/API) and refresh the Stock Cache. This bounds drift and makes cache-based decisions reliable.
The Outbound Sync (Finalizing Orders)
Once an order reaches the “Fulfill” or “Refund” state in the hot path, it needs to be permanently recorded.
A background sync process reads final order state from the Order Cache and writes it to your system of record. This is where you enforce durable invariants: exactly-once accounting, idempotent updates, and audit trails.
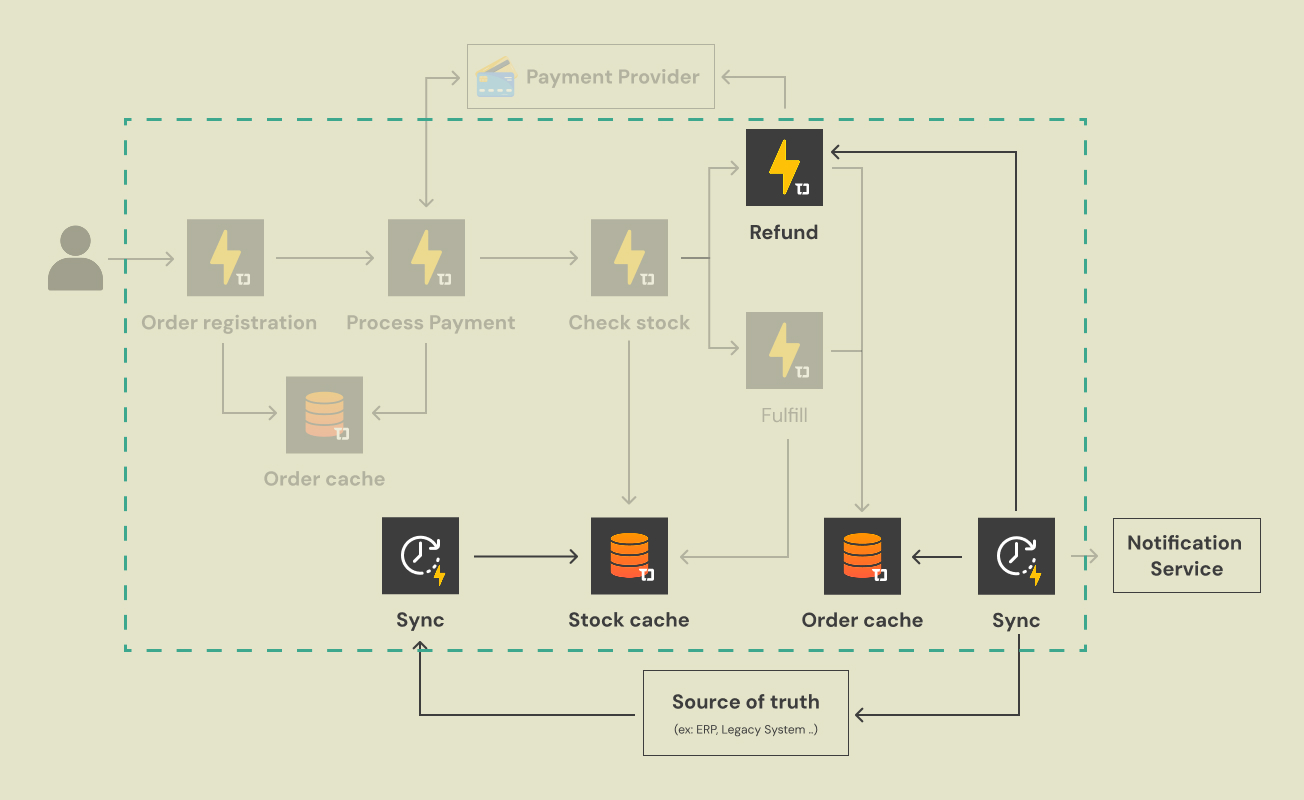 (Caption: The synchronization layer. Background scheduled (timer) functions ensure the fast caches are eventually consistent with the persistent Source of Truth database.)
(Caption: The synchronization layer. Background scheduled (timer) functions ensure the fast caches are eventually consistent with the persistent Source of Truth database.)
Why This Architecture Wins
By adopting this Taubyte-based architecture, we gain significant advantages over traditional serverless approaches:
- Unmatched Speed: Using lightweight functions and distributed caches means the user experience is incredibly snappy, with minimal startup overhead.
- Resilience: If the main “Source of Truth” database goes offline for maintenance, the system can still accept and process orders using the cached data.
- Operational Simplicity: There is no complex console to manage infrastructure. The entire workflow (functions, databases, and timers) is defined in code, making deployments deterministic and instant.
AWS vs Taubyte: Data Sovereignty and Control
For systems architects, sovereignty questions translate into concrete constraints: where workloads run, who operates the control plane, where data is stored/processed, and how hard boundaries are enforced.
Both AWS and Taubyte can support high-scale systems, but they differ significantly in sovereignty posture.
| Topic | AWS (typical managed approach) | Taubyte (self-host or your chosen infrastructure) |
|---|---|---|
| Control plane ownership | Provider-operated control plane for managed services | Autopilot-operated platform under your governance: you control where it runs and the policies; Autopilot handles day‑2 operations on your infrastructure (or a trusted operator’s) |
| Residency boundaries | Region selection + service constraints; still provider infrastructure | Hard boundaries: choose country/region/operator/on‑prem and keep execution/data within that footprint |
| Compliance posture | Shared responsibility model; compliance depends on service selection and configuration | Compliance posture can be aligned to internal controls because execution plane and data plane are operator-controlled |
| Portability / lock-in | Higher when deeply coupled to managed orchestration/datastores | Lower: same model can run across environments you control |
| Failure domains | Bounded by provider regions/services | Architected around your chosen failure domains; can keep hot path operating despite system-of-record outages |
In short: AWS is great when “region choice” is enough. Taubyte is compelling when you need operational control and enforceable residency boundaries, for example, strict data residency, sector regulations, or sovereign deployments.
Architectural Considerations (What Architects Will Care About)
- State model: treat Order Cache as the workflow state machine (e.g.,
registered → paid → reserved → fulfilled/refunded → synced). - Idempotency: every step (payment update, reservation, fulfillment, refund, sync) must be safe to retry.
- Delivery semantics: assume “at-least-once” execution for background jobs; design deduplication keys and idempotent writes.
- Reservation policy: define reservation TTLs, release rules, and reconciliation behavior when the system of record disagrees.
- Consistency guarantees: be explicit about where you require strong consistency (reservation) vs eventual convergence (sync to system of record).
- Back-pressure & throttling: protect payment provider and system-of-record APIs with rate limits and queues.
- Observability: trace an order end-to-end (correlation IDs), expose workflow metrics (conversion, refund rate, reservation contention), and alert on sync lag.
- Security boundaries: isolate secrets (payment keys), minimize PII in caches, and ensure encryption + access controls at rest and in transit.
Conclusion
Building a resilient, low-latency order processing system doesn’t require complex orchestration tools or sacrificing speed for consistency. With Taubyte, you can keep the customer path fast using lightweight functions and distributed caches, while keeping the system of record accurate through background reconciliation.
The architecture we’ve outlined (edge caching for speed, asynchronous synchronization for accuracy) represents a modern approach to e-commerce infrastructure that scales with your business while keeping operational complexity minimal.
Next Steps
Ready to build your own high-performance order processing system? Here’s how to get started:
- Set up Taubyte locally: Install Dream to create a local cloud environment for rapid development and testing
- Define your functions: Start with the order registration function using Taubyte’s HTTP functions
- Configure distributed caches: Set up your Order Cache and Stock Cache using Taubyte’s databases capabilities
- Implement sync workers: Create scheduled (timer) functions for bidirectional synchronization with your source of truth
- Test and deploy: Use Taubyte’s local development tools to test the complete workflow before deploying to production